Public BigQuery
Fast and flexible queries of all Lens data in bulk and on demand.
Introduction
Lens already has indexers, which snapshot the data and transform it into a relational, super easy-to-understand database. This is how we get our speed on queries and how we can power all the LENS apps with the API. This saves the data into a centralised postgres database and allows you to query it using graphQL API. This is perfect for apps which need data on query time; for example, a user who is logging in wants to see their feed or see someone's profile. Querying this through the API is perfect and fast. The complication comes when you wish to bulk pull data, say you wish to do some ML training, some analytic, general data profiling. Right now, you would need a dedicated endpoint to surface that information, and of course, us creating these endpoints, which maybe you are only interested in. This does not scale. On top of this, having all this data and not allowing leverage for builders to do stuff feels wrong.
With this in mind, we have published the entire Lens social graph to a public BigQuery dataset. This means you can query all the data in bulk, whatever you want, in any way you wish, to any demand. Public BigQuery datasets give you a 1TB allowance every month, but if you want more, just add some GCP credits. This information should be accessible by anyone without them having to write the complex task of indexers and have all that infrastructure set up. This solves that, bringing you the entire Lens graph in the cloud to query anytime you wish.
What can I do with this?
You can pull huge data to do analytics say, a creator's analytics dashboard. You can pull huge amounts of day to run some ML code on it to showcase the discovery of publications. You can build your feeds with curated information very easily. This is the first step in allowing anyone to build custom features on top of LENS without the API has to do it for you. Think outside the box. You have the data. Go and build something epic with it.
How to query it
You should read this to understand how you query public data sets from BigQuery https://cloud.google.com/bigquery/public-data. You can do it from the google cloud console or any BigQuery client libraries, which support mostly all languages. The easiest way if you want to play around with it is using the Analytic hub, as you can run queries directly through it.
polygon - lens-public-data.v2_polygon.INSERT_YOUR_TABLE_NAME_HERE
amoy -lens-public-data.v2_amoy.INSERT_YOUR_TABLE_NAME_HERE
REPLACE THE INSERT_YOUR_TABLE_NAME_HERE with the table name
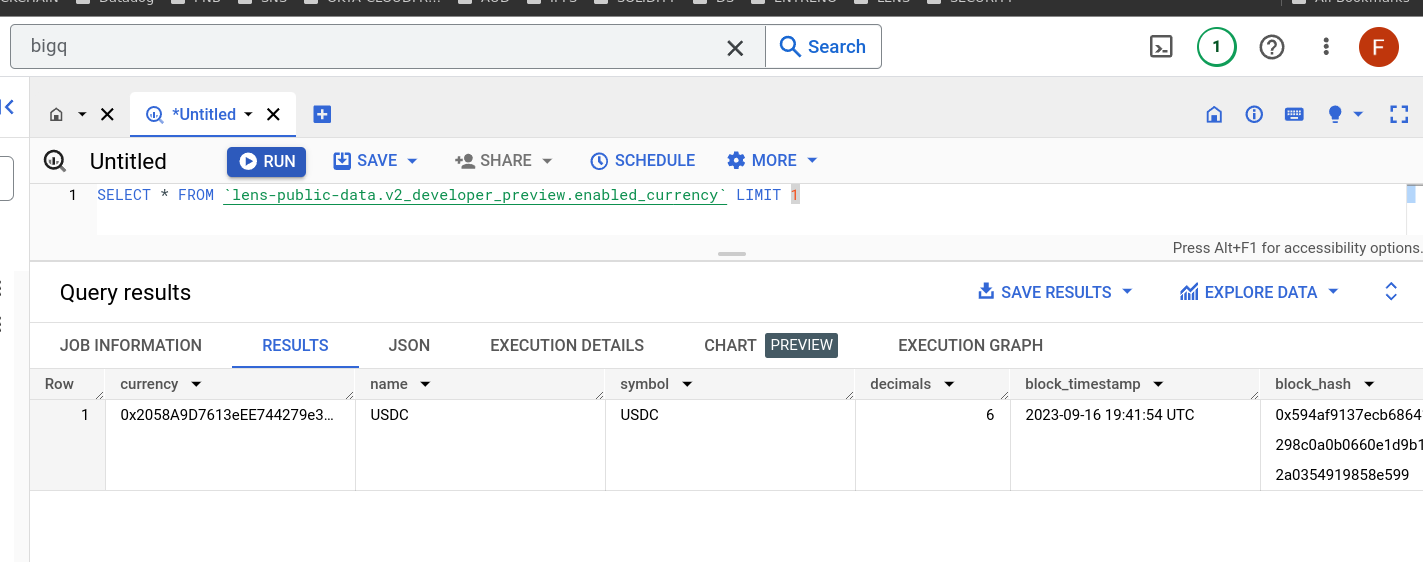
For example, to get all the publications, you can run
SELECT * FROM lens-public-data.v2_polygon.publication_record LIMIT 10
If you want to get all the table names which exist, you can do
SELECT table_name FROM lens-public-data.v2_polygon.INFORMATION_SCHEMA.TABLES
Please note you MUST query this from the US region. If you try to use the EU region it will not be able to find it
How it works
It is very simple how it works. The diagram examples the flows:
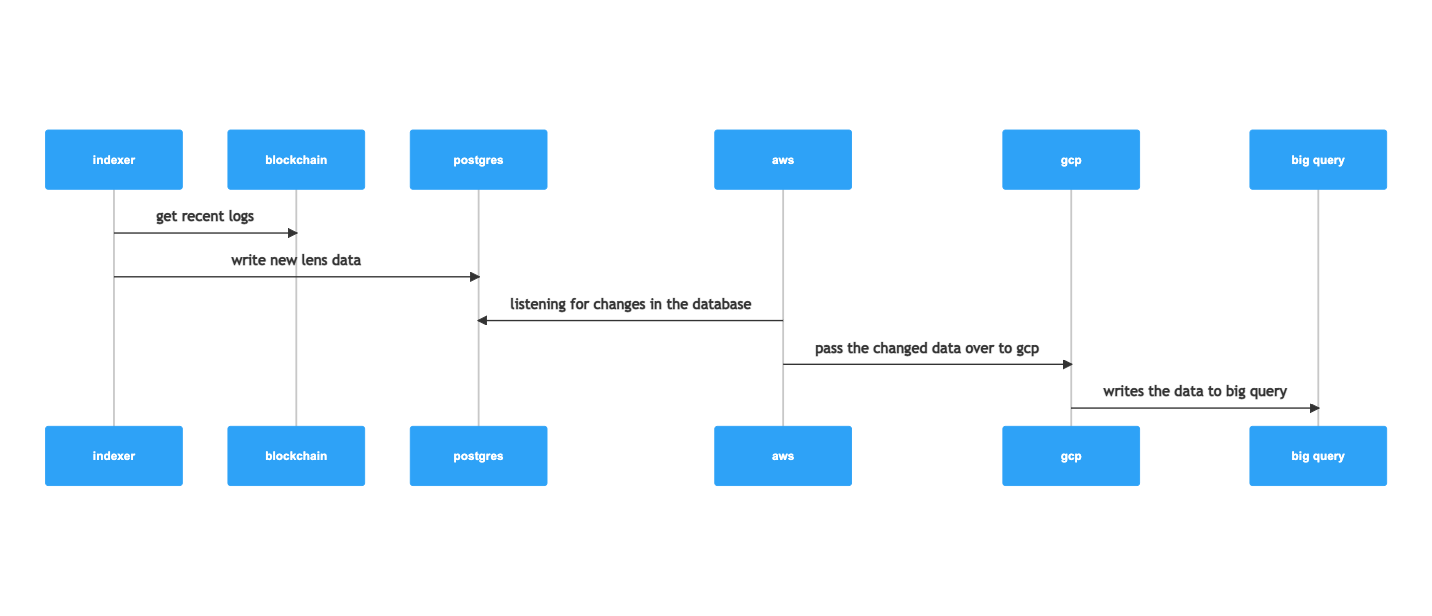
The data will always be 15 minutes behind. This is the fastest setting you can have turned on with the data syncer.
schema
We will dive into the DB setup for you; you can also generate an ERD on BigQuery to see how things lined up. The below will summarise all the tables and their usage; it won't go into full detail about their column types etc., as you can see in BigQuery for that.
In progress....
Updated 14 days ago